用户消费行为数据分析
关于本文的所有数据与代码均已上传至GitHub,也可直接查看:Jupyter nbviewer。
如果文章中有任何错误,非常希望读者能够批评指正!
看到一个用户消费行为价值分析的题目,要求是对数据进行预处理及可视化,然后根据用户的行为,判断用户是否会下单或下单购买的概率。于是我按照数据分析的流程进行分析,使用了Logistic、决策树和支持向量机三种模型去对用户是否下单进行分类,同时也能得到对应的概率。
题目要求如下:
获取数据并进行预处理,提高数据质量;
对用户的各城市分布情况、登录情况进行分析,并分别将结果进行多种形式的可视化展现;
构建模型判断用户最终是否会下单购买或下单购买的概率,并将模型结果输出为csv文件(参照结果输出样sample_output.csv)。要求模型的效果达到85%以上;
通过用户消费行为价值分析,给企业提出合理的建议。
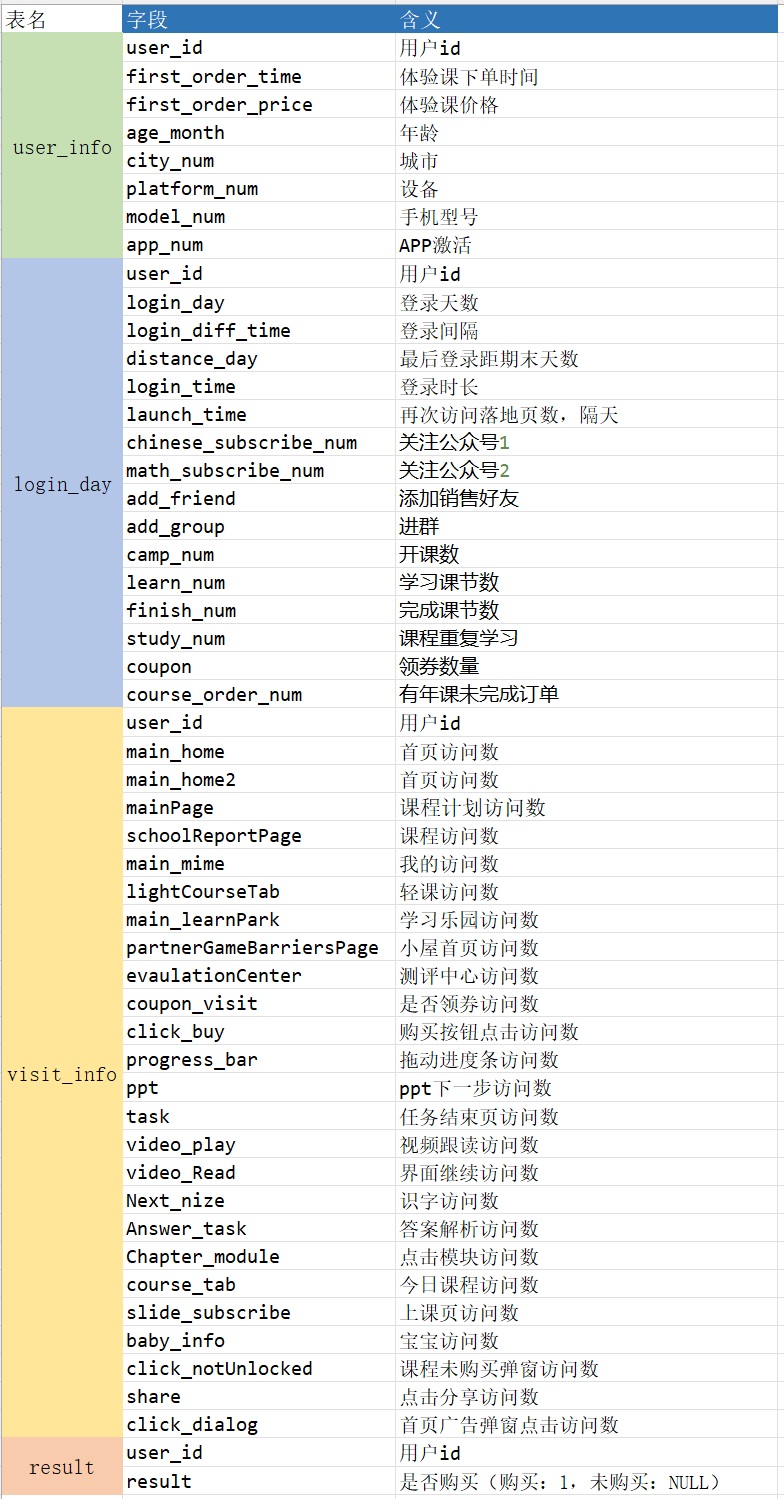
包含数据:
user_info.csv:用户信息表
login_day.csv: 用户登录情况表
visit_info.csv: 用户访问统计表
result.csv: 用户下单表
数据预处理
读取数据的过程就不说了,数据格式均为csv文件,可以用pandas的read_csv方法读取。
首先查看数据的缺失情况,用isnull()和any()方法查看字段是否有缺失。
user_info_df.isnull().any()
>
user_id False
first_order_time False
first_order_price False
age_month False
city_num True
platform_num False
model_num False
app_num False
dtype: bool所有数据中只有城市(city_num)字段有缺失,但是这一类值没有比较好的方法去填充,所以考虑把所有缺失值替换为”unknown”字符串。此外,字段中还有一个例外值为”error”,也同样替换为”unknown”。
user_info = user_info_df.replace('error', np.nan) # 出现error值的替换为NaN
user_info = user_info.fillna('unknown') # 暂时用unknown值填补缺失值随后可以明显的发现年龄这个字段有异常值,正常范围应当处于1~150,这里我将范围缩小到5~100,即这个范围之外的值均为异常值,而正常来说,有的数据集可以使用多种方式来处理,比如用正确的值更正,可以利用回归或者均值填充,也可以丢弃这个样例,但是这里异常的值有比较多,又无法找出相似的样例用均值填充,所以还是决定全换成0,表明是同一种情况。
user_info[(user_info['age_month'] > 100) | (user_info['age_month'] < 7)]
ab_idx = user_info[(user_info['age_month'] > 100) | (user_info['age_month'] < 5)].index
user_info.loc[ab_idx, 'age_month'] = 0至此,数据比较完整,进入下一步。
数据可视化
以下可视化选择的是pyecharts工具
城市
按照用户的城市地区可以绘制城市的分布情况
city_counts = user_info['city_num'].value_counts()
city_counts_list = [[x, y] for x, y in zip(city_counts.index, city_counts.values)]
with open('area_data.json', 'r', encoding='utf-8') as fp:
area_data = json.load(fp)
city_distribution = {}
for k in area_data.keys():
city_distribution[k] = 0
for c in city_counts_list:
for k, v in area_data.items():
for i in v:
if c[0] in i:
city_distribution[k] += c[1]
city_dist = []
for k, v in city_distribution.items():
city_dist.append([k, int(v)]) # 一个坑:原本为numpy.int64数据类型,但是在Map画图中显示不了值,只能先转为int
city_map = (
Map(init_opts=opts.InitOpts(width="800px", height="600px",
chart_id=1, bg_color='#ADD8E6')) # 可切换主题
.set_global_opts(
title_opts=opts.TitleOpts(title="用户城市分布图"),
visualmap_opts=opts.VisualMapOpts(
min_=0,
max_=13000,
range_text=['人数区间:', ''], # 分区间
is_piecewise=True, # 定义图例为分段型,默认为连续的图例
pos_top="middle", # 分段位置
pos_left="left",
orient="vertical",
split_number=8 # 分成8个区间
)
)
.add("城市分布", city_dist, maptype="china")
)年龄
年龄分布按照下面分段进行分类,绘制年龄分布的柱状图
flowchart LR A(0)---|未知|B(1) B---|儿童|C(7) C---|少年|D(18) D---|青年|E(41) E---|中年|F(66) F---|老年|G(101)
age_label = ['未知', '儿童', '少年', '青年', '中年', '老年']
age_fields = pd.cut(user_info['age_month'], [0, 1, 7, 18, 41, 66, 101],
right=False, labels=age_label)
age_lis = list(age_fields.value_counts())
age_prop = [round(x*100/sum(age_lis), 2) for x in age_lis]
age_bar = (
Bar(init_opts=opts.InitOpts(width="800px", height="600px",
chart_id=2, bg_color='#ADD8E6'))
.add_xaxis(age_label)
.add_yaxis(
series_name="各年龄阶段人数",
y_axis=age_lis,
label_opts=opts.LabelOpts(position='inside')
)
.add_yaxis(
series_name="各年龄阶段占比",
y_axis=age_prop,
yaxis_index=1,
label_opts=opts.LabelOpts(formatter="{c} %", position='inside')
)
.extend_axis(
yaxis=opts.AxisOpts(
name="百分比",
type_="value",
interval=10,
axislabel_opts=opts.LabelOpts(formatter="{value} %")
)
)
.set_global_opts(
yaxis_opts=opts.AxisOpts(
name="人数",
type_="value"
),
title_opts=opts.TitleOpts("年龄分布柱状图")
)
)下单金额
统计出数据中每月的订单金额,顺便计算出每月的用户人均付费。
user_info['first_order_time'] = pd.to_datetime(user_info['first_order_time']) # 转换为datetime数据类型
order_tl = Timeline(init_opts=opts.InitOpts(chart_id=3))
for yr in range(2018, 2020):
yr_df = user_info[user_info['first_order_time'].dt.year == yr][['first_order_time', 'first_order_price']]
x_month = yr_df['first_order_time'].dt.month.sort_values().unique().astype('int')
y_price = [yr_df[yr_df['first_order_time'].dt.month == p]['first_order_price'].sum() for p in x_month]
avg_price = [round(yr_df[yr_df['first_order_time'].dt.month == p]['first_order_price'].mean(), 2) for p in x_month]
yr_bar = (
Bar(init_opts=opts.InitOpts(width="800px", height="600px",
bg_color='#ADD8E6'))
.add_xaxis([str(m) + '月' for m in x_month])
.add_yaxis("月度收入", y_price)
.add_yaxis("人均付费(ARPU)", avg_price, yaxis_index=1)
.extend_axis(yaxis=opts.AxisOpts(type_="value"))
.set_global_opts(title_opts=opts.TitleOpts(f"{yr}年订单金额"))
)
order_tl.add(yr_bar, "{}年".format(yr))饼图
饼图是针对具有分类意义的字段,即使值可能是数值型,如是否关注公众号1、是否添加销售好友等,用饼图展现用户在这方面的占比情况。
pie_data_x = ["否", "是"]
chinese_sub_y = login_day['chinese_subscribe_num'].value_counts()
math_sub_y = login_day['math_subscribe_num'].value_counts()
add_friend_y = login_day['add_friend'].value_counts()
add_group_y = login_day['add_group'].value_counts()
study_num_y = login_day['study_num'].value_counts()
chinese_sub_pair = [list(z) for z in zip(pie_data_x, chinese_sub_y)]
math_sub_pair = [list(z) for z in zip(pie_data_x, math_sub_y)]
add_friend_pair = [list(z) for z in zip(pie_data_x, add_friend_y)]
add_group_pair = [list(z) for z in zip(pie_data_x, add_group_y)]
study_num_pair = [list(z) for z in zip(pie_data_x, study_num_y)]
fn = """
function(params) {
if(params.name == '否')
return '\\n\\n\\n' + params.name + ' : ' + params.value;
return params.name + ' : ' + params.value;
}
"""
sub_pie = (
Pie(init_opts=opts.InitOpts(width="800px", height="600px",
chart_id=4, bg_color='#ADD8E6'))
.add(
series_name="关注公众号1",
data_pair=chinese_sub_pair,
center=["20%", "30%"],
radius=[50, 80],
label_opts=opts.LabelOpts(formatter=JsCode(fn), position="center")
)
.add(
series_name="关注公众号2",
data_pair=math_sub_pair,
center=["50%", "30%"],
radius=[50, 80],
label_opts=opts.LabelOpts(formatter=JsCode(fn), position="center"),
)
.add(
series_name="添加销售好友",
data_pair=add_friend_pair,
center=["80%", "30%"],
radius=[50, 80],
label_opts=opts.LabelOpts(formatter=JsCode(fn), position="center"),
)
.add(
series_name="进群",
data_pair=add_group_pair,
center=["35%", "70%"],
radius=[50, 80],
label_opts=opts.LabelOpts(formatter=JsCode(fn), position="center"),
)
.add(
series_name="重复学习",
data_pair=study_num_pair,
center=["65%", "70%"],
radius=[50, 80],
label_opts=opts.LabelOpts(formatter=JsCode(fn), position="center"),
)
.set_global_opts(title_opts=opts.TitleOpts("饼图"))
)购买课程
最终购买下单的用户比例,选择用水球图来展现。
purchase_liquid = (
Liquid(init_opts=opts.InitOpts(width="800px", height="600px",
chart_id=5, bg_color='#ADD8E6'))
.add(
"购买率",
[round(len(result)/len(user_info), 4)],
label_opts=opts.LabelOpts(
formatter=JsCode("function(param) {return (Math.floor(param.value * 10000) / 100) + '%';}"),
position="inside"
)
)
.set_global_opts(title_opts=opts.TitleOpts(title="购买课程比例"))
)模型建立与求解
1.数据处理(特征选择)
数据涉及到多个表,为便于模型的处理,要将字段根据用户ID(user_id)整合到一个DataFrame数据集中。
判断用户是否会下单购买,这是一个二分类的问题,可以选择逻辑回归、决策树、支持向量机等方法,这里我就是选用这几种模型进行求解。构建模型前,还需要进行特征的选择或者说筛选,目的是剔除对模型分类用处不大的特征,这样能够提高模型的效率及准确性。
初步可以直接剔除无法量化的字符型字段及时间类型字段,从之前的数据预处理阶段还能发现许多字段分布几乎只有一种值,比如APP是否激活等,这样的特征也需要去除。
# user_info, login_day, visit_info
# 将数据字段进行整合处理,并筛选用于离散选择模型的特征
ul_merge = pd.merge(user_info, login_day, on='user_id') # 合并数据表
all_fields = pd.merge(ul_merge, visit_info, on='user_id')
all_fields['result'] = all_fields['user_id'].apply(lambda x: 1 if x in result['user_id'].values else 0)
drop_fea = ['first_order_time', 'city_num', 'platform_num', 'model_num',
'app_num', 'add_friend', 'add_group', 'launch_time']
# 去除非数值型的字段,app_num字段值全为1,对模型的拟合没有多大用处,也去除
all_fields.drop(drop_fea, axis=1, inplace=True)其次也不难发现有的字段有比较高的相关性,比如学习课节数和完成课节数,这两者的相关系数竟达到了0.9,所以也需要去除其一。完整的筛选出所有字段中相关系数大于0.8的,进行手动的筛选,列出需要去除的字段drop_fea2。
fields_corrs = all_fields.iloc[:, 1:-1].corr()
large_corr = []
for i in range(fields_corrs.shape[0]):
for j in range(i+1, fields_corrs.shape[1]):
if fields_corrs.iloc[i, j] > 0.8: # 找出相关性大于0.8的字段
large_corr.append([fields_corrs.index[i], fields_corrs.columns[j], fields_corrs.iloc[i, j]])
drop_fea2 = ['main_home2', 'main_mime', 'click_buy', 'first_order_price']
all_fields.drop(drop_fea2, axis=1, inplace=True)字段筛选完毕,之后就要将数据分割为训练集和测试集,使用的是sklearn.model_selection中的train_test_split方法.
x_train, x_test, y_train, y_test = train_test_split(all_fields.iloc[:, 1:-1],
all_fields['result'],
test_size=0.2,
stratify=all_fields['result'],
random_state=0)2.预备知识
混淆矩阵
在二分类问题中,把实际的结果和预测的结果整理成表格(矩阵)可以比较直观的看到分类表现,类似于下表。
其中字母的含义可以联想对应的英语单词:T(True)、F(False)、P(Positive)、N(Negative)。
这种规律也很好记忆,先看预测表现,预测为正例则为P(Positive),否则为N(Negative),再看实际表现与预测表现是否一样,一样则预测正确为T(True),否则为F(False)。
准确率
准确率表示预测正确样本个数占总样本的比例,按上面公式写就是:
在机器学习的分类问题中,直接用准确率判断模型的好坏并不总是合适的,要考虑一个样本平衡的问题。
举例说明:如果在一个总样本中,正样本占90%,负样本占10%,这时样本是的占比是不平衡的。在这种情况下,直接把全部样本都预测为正样本都能有90%的准确率,但明显这样分类是不合适的。在这个例子中样本极不平衡,用准确率衡量分类模型性能就没有什么说服力。
精准率
精准率(Precision)又叫查准率,不同于准确率针对的是总样本,精准率的含义是在所有被预测为正的样本中实际为正的样本的比例。
和准确率对比是很容易发现区别的,精准率代表对正样本结果中的预测准确程度。
召回率
召回率(Recall)又叫查全率,含义是在实际为正的样本中被预测为正样本的比例。
召回率是覆盖面的度量,度量有多少实际正例被预测为正例。
F1分数
精准率和召回率通常一高一低,而我们则希望让两者都尽可能高,不至于是极端。而F1分数(F1-score)是一个指标,同时考虑精准率和召回率,让二者都比较高。
F1-Score越高,可以说明模型越稳健。
灵敏度、特异度、真正率、假正率
这里发现灵敏度和特异度公式是一样的,只是名字不同。
这里发现TPR和FPR分别是基于实际表现出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,无论样本是否平衡,都不会被影响,而ROC/AUC指标也就是用TPR和FPR来衡量的。
ROC曲线与AUC值
ROC曲线是基于混淆矩阵得出的,横轴为假正率,纵轴为真正率。对于分类器,它输出的是判别样本为各个类别的概率,那么判别样本为某一类就要定义一个阈值,大于该阈值归为正类等,这个阈值并不是直接随意定义,要找一个最好的阈值让分类的效果最好,于是遍历预测的概率中的所有阈值,得到对应阈值下的真正率和假正率,就可以得到一系列这样的值,画出来就得到了ROC曲线。
FPR表示模型虚报的响应程度,而TPR表示模型预测响应的覆盖程度。我们所希望的当然是:虚报的越少越好,覆盖的越多越好。所以总结一下就是TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。
而AUC值表示的是ROC曲线下面积。作为对比的是通常画ROC曲线时还会画
y=x这条直线(连接对角线),它的面积为0.5,表示的是随机效果。AUC的一般判断标准:
0.5 ~ 0.7 :效果较低
0.7 ~ 0.85 :效果一般
0.85 ~ 0.95:效果很好
0.95 ~ 1 :效果非常好
2.Logistic
Logistic
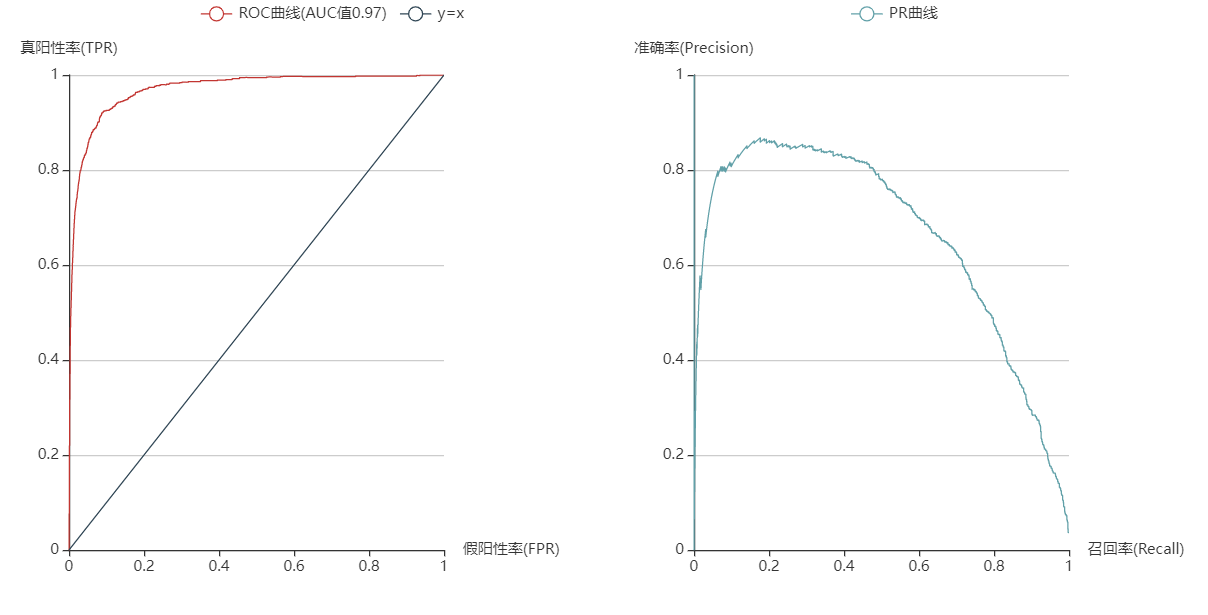
使用sklearn中线性模型中的LogisticRegression构建逻辑回归模型。模型的求解算法选择’newton-cg’,原因是线性求解器’liblinear’适合于较小数据集,这里样本量达到了13万,所以选择适合大数据集的牛顿法来作为求解器,分类的效果也是不错的。
logit_clf = LogisticRegression(solver='newton-cg') # 使用牛顿法求解器
logit_clf.fit(x_train, y_train) # 拟合训练集
logit_prob = logit_clf.predict_proba(x_test) # 预测测试集类别的概率
logit_pred = logit_clf.predict(x_test) # 预测测试集的类别
logit_fpr, logit_tpr, _ = roc_curve(y_test, logit_prob[:, 1]) # 得到真假阳性率数据
logit_area = round(roc_auc_score(y_test, logit_prob[:, 1]), 3) # AUC值,保留3位小数
logit_precision, logit_recall, _ = precision_recall_curve(y_test, logit_prob[:, 1]) # 得到准确率和召回率的数据
logit_acc = logit_clf.score(x_test, y_test) # 返回的是测试集预测类别与实际类别的准确度可视化代码:
# 对模型进行评估与可视化
logit_roc_line = (
Line()
.add_xaxis(logit_fpr)
.add_yaxis(
series_name=f'ROC曲线(AUC值{logit_area})',
y_axis=logit_tpr,
is_symbol_show=False,
is_smooth=True
)
.add_yaxis(
series_name='y=x',
y_axis=logit_fpr,
is_symbol_show=False
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="假阳性率(FPR)"),
yaxis_opts=opts.AxisOpts(
name="真阳性率(TPR)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True,
),
legend_opts=opts.LegendOpts(pos_left="20%")
)
)
logit_pr_line = (
Line()
.add_xaxis(logit_recall)
.add_yaxis(
series_name='PR曲线',
y_axis=logit_precision,
is_symbol_show=False,
is_smooth=True
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="召回率(Recall)"),
yaxis_opts=opts.AxisOpts(
name="准确率(Precision)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True
),
legend_opts=opts.LegendOpts(pos_right="20%")
)
)
# roc_pr_line = roc_line.overlap(pr_line)
logit_roc_pr_line = (
Grid(init_opts=opts.InitOpts(width="1000px", height="500px"))
.add(logit_roc_line, grid_opts=opts.GridOpts(pos_right="60%"))
.add(logit_pr_line, grid_opts=opts.GridOpts(pos_left="60%"))
)
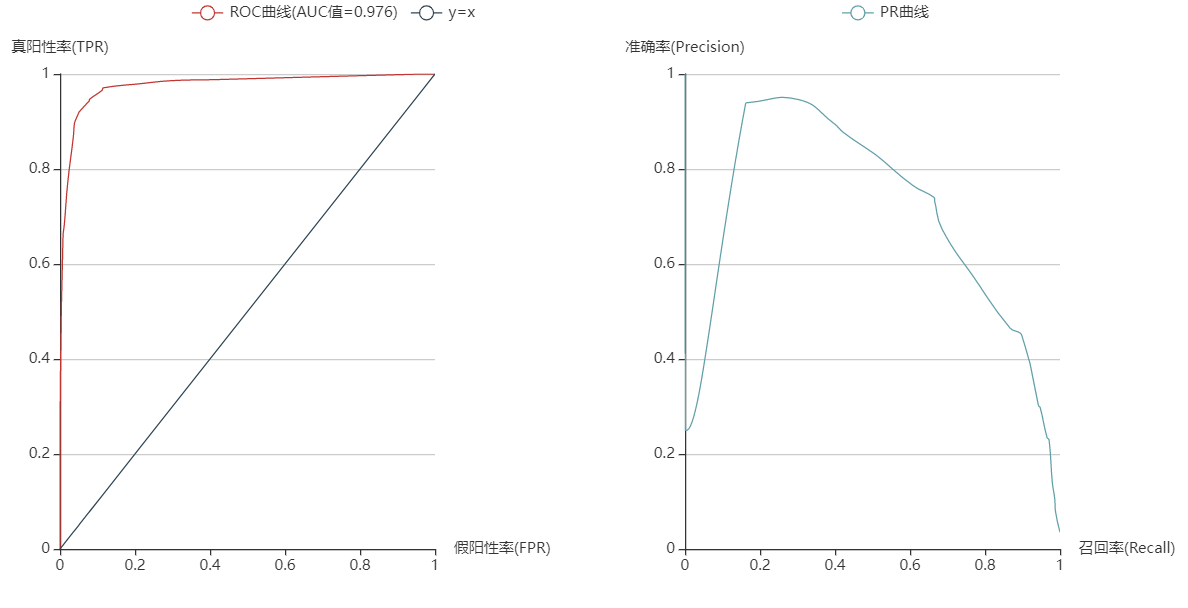
3.决策树
决策树
使用决策树进行分类的优点是易于解释、方便可视化等优点,当然缺点也明显,容易过拟合等。
# 采用决策树模型进行分类
# 使用信息熵作为划分标准,最大深度为5,对决策树进行训练
tree_clf = tree.DecisionTreeClassifier(criterion='entropy',
max_depth=5, random_state=0)
tree_fit = tree_clf.fit(x_train, y_train) # 拟合训练集
with open("tree.dot", 'w') as f: # 保存决策树的结果,后续进行可视化
f = tree.export_graphviz(tree_fit, out_file=f,
feature_names=x_train.columns,
class_names=[str(cl) for cl in tree_fit.classes_],
filled=True, rounded=True,
special_characters=True)
with open("tree.dot", 'r') as fp:
dot_code = fp.read()
graph = pydotplus.graph_from_dot_data(dot_code)
graph.write_pdf("tree.pdf") # pydotplus对决策树的代码进行可视化,生成PDF文件
tree_pred = tree_clf.predict(x_test) # 预测测试集类别
tree_prob = tree_clf.predict_proba(x_test) # 测试集类别的概率
tree_fpr, tree_tpr, _ = roc_curve(y_test, tree_prob[:, 1]) # 得到真假阳性率数据
tree_area = round(roc_auc_score(y_test, tree_prob[:, 1]), 3) # AUC值,保留3位小数
tree_precision, tree_recall, tree_thresholds = precision_recall_curve(y_test, tree_prob[:, 1]) # 得到准确率和召回率的数据
tree_acc = tree_clf.score(x_test, y_test) # 模型精度可视化代码:
# 对模型进行评估与可视化
tree_roc_line = (
Line()
.add_xaxis(tree_fpr)
.add_yaxis(
series_name=f'ROC曲线(AUC值={tree_area})',
y_axis=tree_tpr,
is_symbol_show=False,
is_smooth=True
)
.add_yaxis(
series_name='y=x',
y_axis=tree_fpr,
is_symbol_show=False
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="假阳性率(FPR)"),
yaxis_opts=opts.AxisOpts(
name="真阳性率(TPR)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True,
),
legend_opts=opts.LegendOpts(pos_left="20%")
)
)
tree_pr_line = (
Line()
.add_xaxis(tree_recall)
.add_yaxis(
series_name='PR曲线',
y_axis=tree_precision,
is_symbol_show=False,
is_smooth=True
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="召回率(Recall)"),
yaxis_opts=opts.AxisOpts(
name="准确率(Precision)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True
),
legend_opts=opts.LegendOpts(pos_right="20%")
)
)
tree_roc_pr_line = (
Grid(init_opts=opts.InitOpts(width="1000px", height="500px"))
.add(tree_roc_line, grid_opts=opts.GridOpts(pos_right="60%"))
.add(tree_pr_line, grid_opts=opts.GridOpts(pos_left="60%"))
)
其次,还能够得到决策树分类中特征的重要性,值越大表示对分类的效果越好,越能区分类别。得到如下图:
从上面也能得出一些小小的结论:领券对用户是否下单有着非常重要的影响。
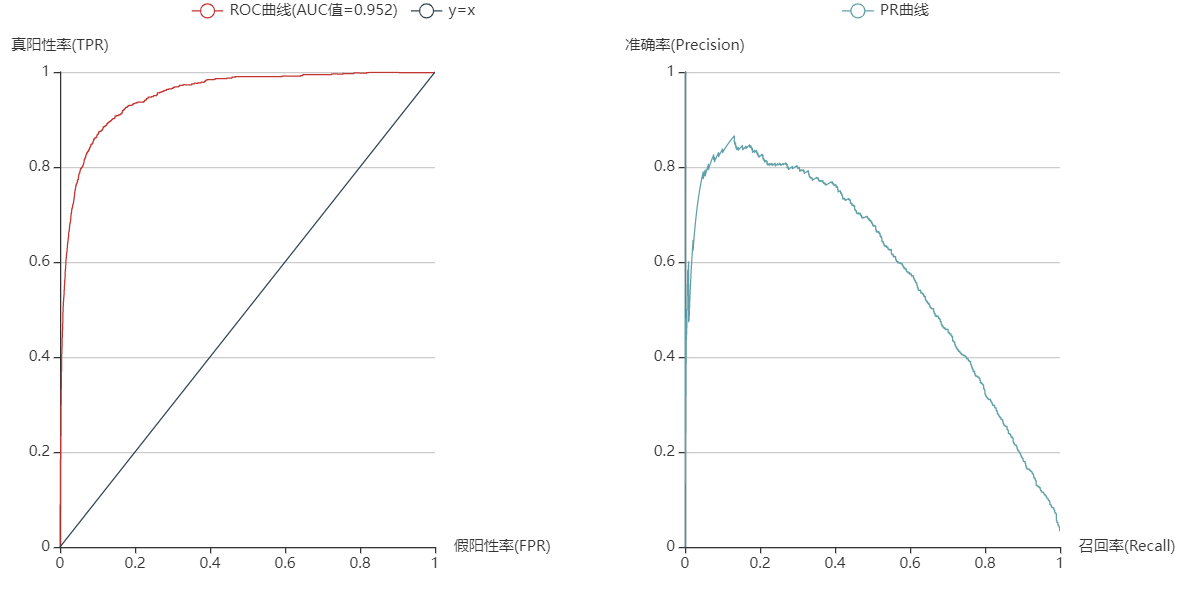
4.支持向量机
支持向量机
sklearn中的svm模块有SVC和LinearSVC两种模型,在选择的时候要考虑它们的区别:
LinearSVC
基于liblinear库实现
有多种惩罚参数和损失函数可供选择
训练集实例数量大(大于1万)时也可以很好地进行归一化
既支持稠密输入矩阵也支持稀疏输入矩阵
多分类问题采用one-vs-rest方法实现
SVC
基于libsvm库实现
训练时间复杂度为
训练集实例数量大(大于1万)时很难进行归一化
多分类问题采用one-vs-rest方法实现
很明显对于超过10万的样本量应当选择LinearSVC会更合适。同时也尝试了二者的效果,发现LinearSVC的准确度比SVC要高一些,并且训练时间也远少于SVC(8.11s VS 15min 36s)。
LinearSVC实现代码如下:
lsvm_clf = LinearSVC(dual=False, random_state=0) # 样本量大于特征数,将对偶项设为False
lsvm_clf.fit(x_train, y_train) # 拟合训练集
lsvm_pred = lsvm_clf.predict(x_test) # 预测测试集
lsvm_prob = lsvm_clf._predict_proba_lr(x_test) # 测试集类别的概率
lsvm_fpr, lsvm_tpr, _ = roc_curve(y_test, lsvm_prob[:, 1]) # 得到真假阳性率数据
lsvm_area = round(roc_auc_score(y_test, lsvm_prob[:, 1]), 3) # AUC值,保留3为小数
lsvm_precision, lsvm_recall, _ = precision_recall_curve(y_test, lsvm_prob[:, 1]) # 准确率与回归率
lsvm_acc = lsvm_clf.score(x_test, y_test) # 模型精度可视化代码:
# 对模型进行评估与可视化
lsvm_roc_line = (
Line()
.add_xaxis(lsvm_fpr)
.add_yaxis(
series_name=f'ROC曲线(AUC值={lsvm_area})',
y_axis=lsvm_tpr,
is_symbol_show=False,
is_smooth=True
)
.add_yaxis(
series_name='y=x',
y_axis=lsvm_fpr,
is_symbol_show=False
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="假阳性率(FPR)"),
yaxis_opts=opts.AxisOpts(
name="真阳性率(TPR)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True,
),
legend_opts=opts.LegendOpts(pos_left="20%")
)
)
lsvm_pr_line = (
Line()
.add_xaxis(lsvm_recall)
.add_yaxis(
series_name='PR曲线',
y_axis=lsvm_precision,
is_symbol_show=False,
is_smooth=True
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="召回率(Recall)"),
yaxis_opts=opts.AxisOpts(
name="准确率(Precision)",
splitline_opts=opts.SplitLineOpts(is_show=True),
is_scale=True
),
legend_opts=opts.LegendOpts(pos_right="20%")
)
)
lsvm_roc_pr_line = (
Grid(init_opts=opts.InitOpts(width="1000px", height="500px"))
.add(lsvm_roc_line, grid_opts=opts.GridOpts(pos_right="60%"))
.add(lsvm_pr_line, grid_opts=opts.GridOpts(pos_left="60%"))
)
5.对比与结论
上述3个模型做完之后,进行一个效果对比,看哪个模型对分类的效果是最好的。
| Logit | Tree | SVM | |
|---|---|---|---|
| 准确度 | 0.978 | 0.98 | 0.971 |
| 精准率 | 0.816 | 0.74 | 0.831 |
| 召回率 | 0.46 | 0.664 | 0.185 |
| F1-Score | 0.589 | 0.7 | 0.303 |
| ROC-AUC | 0.97 | 0.976 | 0.952 |
| PR-AUC | 0.656 | 0.694 | 0.577 |
| 拟合时间 | 13.6s | 576ms | 8.54s |
为了更直观比较,画了个柱状图来对比。
上表中的AUC两栏是不同评估指标,分别是ROC曲线和PR曲线中曲线以下部分的面积,代表了模型的分类表现,将前面三个模型各自的曲线整合到一起更容易在模型之间比较。
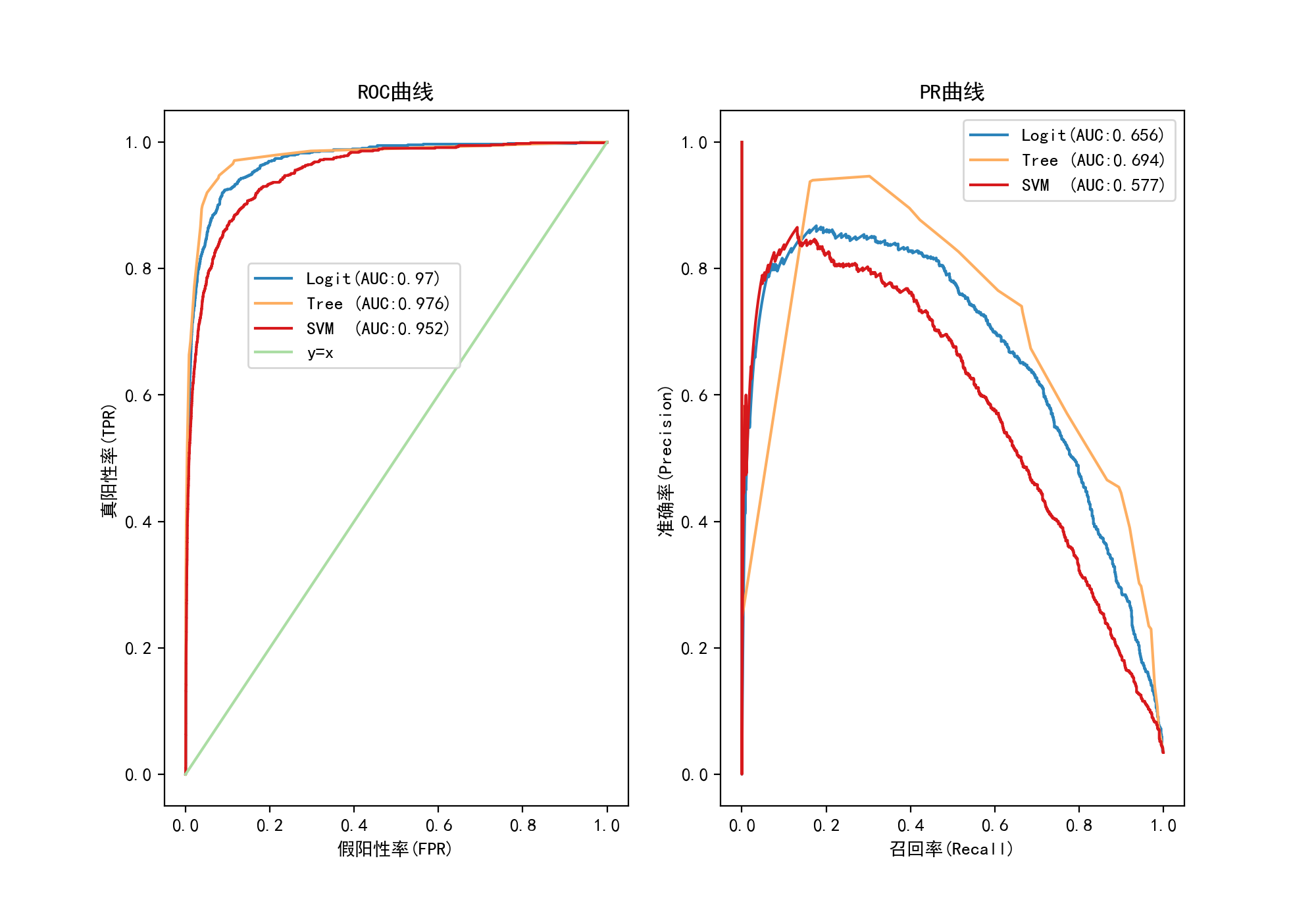
查看一些文章,我发现在不同情况下这两个指标应当选择性的进行对比。
- ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
- 如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
- 如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
- 类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
- 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
不过在这里比较明显的是决策树的表现效果是最好的,准确度达0.98,拟合时间也远低于其他两个模型,虽然精准率稍低于其他两个模型,但结合召回率看,决策树模型的F1分数是最高的,因此有理由认为决策树分类器是较于其他两个分类器效果更佳。
总结与建议
结合前面构建的模型,采用决策树分类器对用户是否会下单进行预测的效果最佳。从用户的所有行为数据中,筛选掉一些对分类帮助不大的数据,构建决策树分类器,可以较为准确的预测用户的下单概率。其中领券数量这一数据项最为突出,其相对于其他数据项更能帮助区分用户是否下单,可知优惠券对用户下单的影响之大,其之后的几个数据项也对分类较为重要。
因此,公司首先可以针对产品设计优惠活动,形式不限,激发用户的购买心理;其次还需要增加用户的留存率,具体提现在APP功能的优化、用户需求的满足,尽可能的留住活跃用户;最后还需回归产品本身,可以收集用户反馈,完善产品不足之处。这些可以根据构建的决策树分类器中特征的重要性进行对症下药,精准的提升用户下单概率。


