ChatGPT的初探与使用
前言
最近的chatgpt智能聊天AI真的是太火了,微信公众号、BiliBili都能看到博主在展示自己与chatgpt的聊天截图,感叹它的强大。当然也有深度测试过的大佬发现chatgpt也并不是非常智能,只能说目前和其他的聊天机器人相比智能太多了,chatgpt也存在着许多不足,比如有时回答的问题根本就是错误的,需要你自己去指出错误,此时它就会立马回道:
那我错了。您说的是对的......马上就认错,但有的网友表明,它有时并不能改正错误,问完问题,再问相同的问题回答的还是和之前的错误答案一样。

但不管怎样,chatgpt确实让许多人震惊,它能回答的问题太多了,会写代码、能写文章,也听说过有外国人拿自己想问的问题让chatgpt回答,把结果和Google搜索的结果相比,认为chatgpt的回答完爆了Google搜索给出的答案,发出“Google Done”的感叹。
也不说别人的感受了,自己上手体验才是最重要的😊。要使用chatgpt目前需要有一个国外的手机号接收验证码来注册,我是使用国外的接码平台SMS-Activate,花了大概11卢布,差不多1元钱,还是可以接受的,具体的注册教程网上有非常多,就不记录了。
关键在于现在就有很多的关于chatgpt的开源项目,我也利用OpenAI开放的接口来探索了一番。
把chatgpt搬到python中
1.模型探索
我首先在OpenAI的接口文档中找到了模型的介绍,主要的模型有三种:
| 模型 | 描述 |
|---|---|
| GPT-3 | 一组可以理解和生成自然语言的模型 |
| Codex | 一组可以理解和生成代码的模型,包括将自然语言转换为代码 |
| Content filter | 一个经过微调的模型,可以检测文本是敏感的还是不安全的 |
以下主要是在官方文档中的翻译内容,了解一下就行了。
GPT-3
| 型号 | 描述 | 最大请求 |
| ———————— | —————————————————————————————— | ———— |
| text-davinci-003 | 是GPT-3模型中最强大的,可以做任何其他模型可以做的任务,往往具有更高的质量、更长的输出和更好的遵循指令。也支持在文本中插入补全句子,使其语义更连贯。 | 4000字符 |
| text-curie-001 | 非常有能力,但比 Davinci 更快,成本更低。 | 2048字符 |
| text-babbage-001 | 能够完成简单的任务,速度快,成本低 | 2048字符 |
| text-ada-001 | 能够完成非常简单的任务,通常是 GPT-3系列中最快的型号,成本最低。 | 2048字符 |虽然Davinci通常是最好用的,其他型号可以非常好地执行某些任务,具有显著的速度或成本优势。例如,Curie可以执行许多与Davinci相同的任务,但速度更快,成本只有Davinci的十分之一。
建议在实验时使用 Davinci,因为它会产生最好的结果。一旦开始工作,鼓励尝试其他模型,看看是否能以较低的延迟获得相同的结果。还可以通过在特定任务上对其他模型进行微调来改进它们的性能。
Codex
Codex 模型是我们可以理解和生成代码的 GPT-3模型的后代。他们的培训数据包含自然语言和来自 GitHub 的数十亿行公共代码。了解更多。
他们最擅长 Python,精通十几种语言,包括 JavaScript、 Go、 Perl、 PHP、 Ruby、 Swift、 TypeScript、 SQL,甚至是 Shell。
后续补充更新。
Content Filter
过滤器旨在检测来自 API 的敏感或不安全的生成文本。它目前处于测试模式,有三种方式来分类文本-安全,敏感,或不安全。过滤器会犯错误,我们目前已经建立了它的错误,在谨慎的一边,因此,导致更高的假阳性。后续补充更新。
2.用Flask实现在线聊天
了解了模型和接口调用后,就可以用Flask把接口所需参数包装一下调用,更方便的聊天。在这之前还需要找一个网页模板。
Flask路由函数
按照OpenAI官方的接口调用方法,写一个/ask的get请求接口,请求参数主要为prompt,表示问的问题,返回回答。@app.route('/ask') def ask(): p = request.args.get('prompt', '') eng = request.args.get('engine', 'text-davinci-003') max_token = int(request.args.get('max_tokens', 256)) if not p: return "" response = openai.Completion.create( engine=eng, prompt=p, temperature=0.3, max_tokens=max_token, n=1 ) return jsonify(result=response["choices"][0]["text"])
前端页面请求
我一个不懂前端的小白,即便找到一个页面模板,也还是搞了好久才把前端后端整合起来。来看下效果吧,默认是用text-davinci-003模型。 上面让AI写一首古诗,结果不知从哪搬来了《春江花月夜》,要是我不认识的诗,还真会以为是AI自己写的呢,估计其他诗也都是网络上搬的。也可以更换模型,不过试了下,其他模型效果也确实不敢恭维,真就是。
上面让AI写一首古诗,结果不知从哪搬来了《春江花月夜》,要是我不认识的诗,还真会以为是AI自己写的呢,估计其他诗也都是网络上搬的。也可以更换模型,不过试了下,其他模型效果也确实不敢恭维,真就是。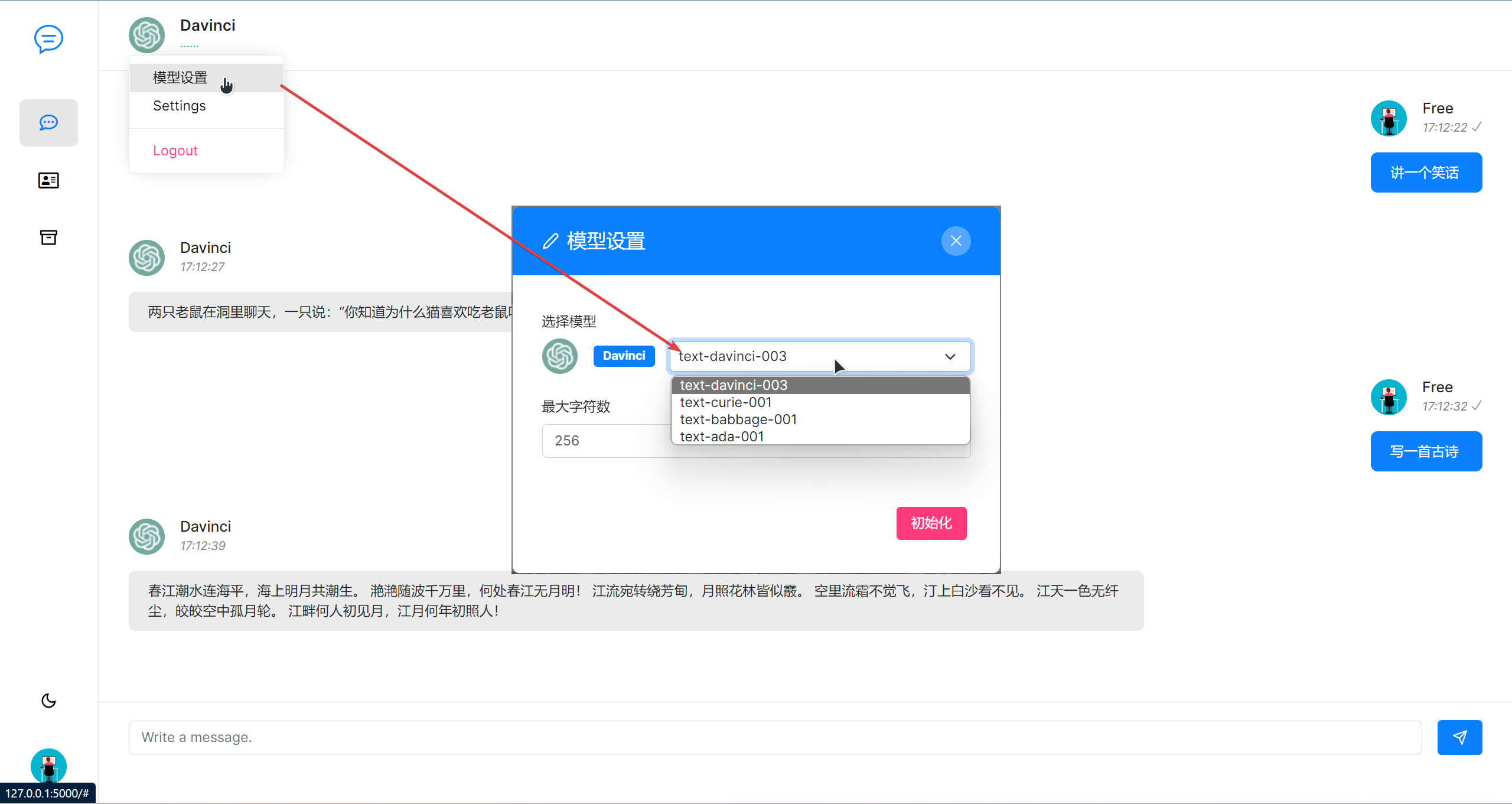
用Ada模型聊天可以看下图,AI的回复有时候都不是一句完整的句子。

- 部署
最后是部署到了Azure中,网站是Slek - Chat and Discussion Platform (webgptchat.azurewebsites.net),可以自行体验下,不过目前还是有些bug。另外使用OpenAI接口是有18美元的免费额度,调用接口会有计费,目前也还能用一阵子。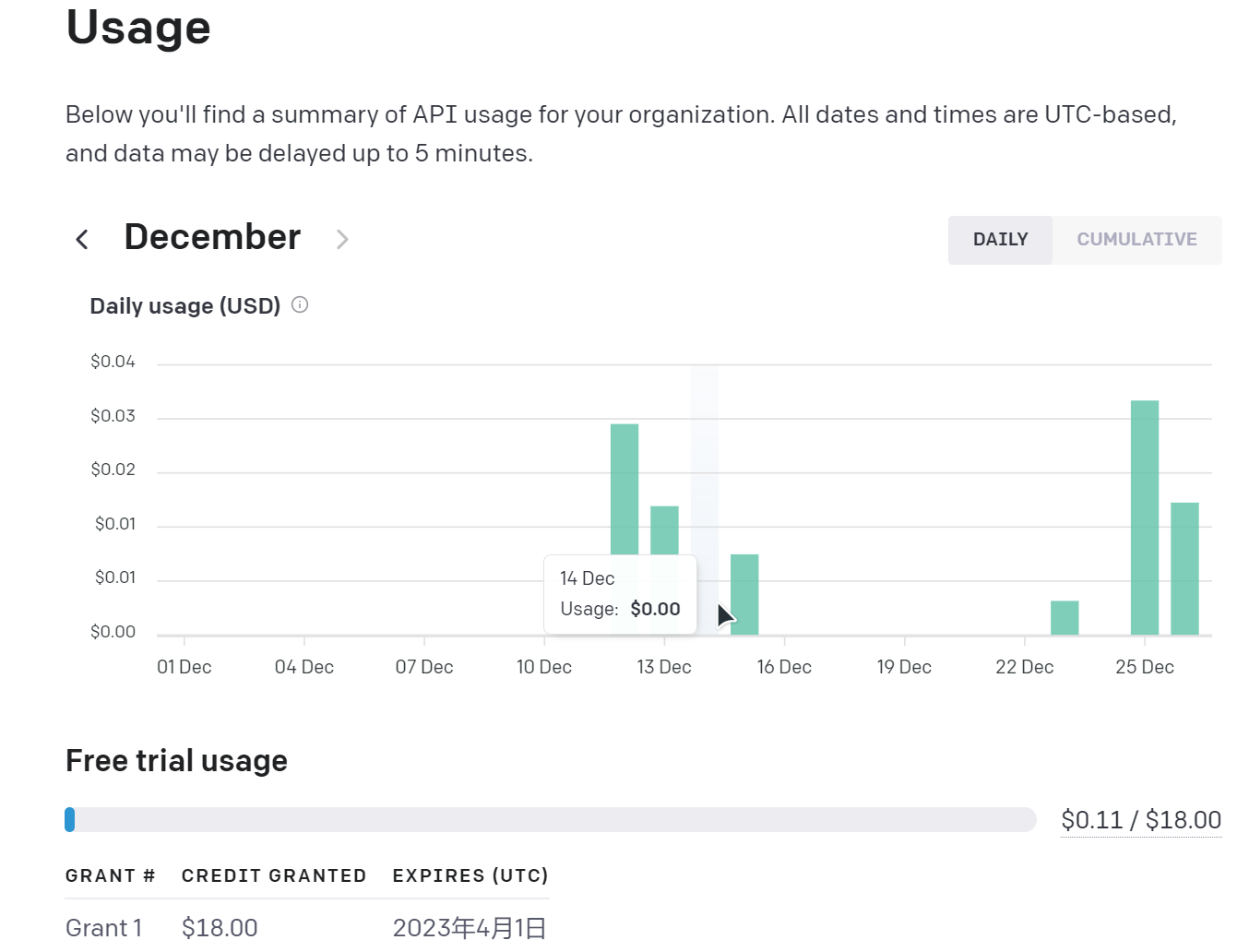
总结
上面只是用OpenAI一部分接口来实现聊天,效果一般,且没有上下文的联系,但在网页上和ChatGPT聊天时就不一样,会有上下文关联,能生成代码等等,应该就是结合了多个模型的结果,而我上面只是用了一部分接口的结果,所以效果没得比。后续有空会继续完善这个聊天的Web项目,添加OpenAI其他接口,比如代码生成等,也会加入其他的聊天接口。